谈谈Agent Skills的底层原理
自去年10月推出以来,Agent Skills迅速成为Claude Agent产品的核心组件,并在社区中得到了广泛的采纳和应用。关于Skills的介绍,网上已经有很多文章。本文尝试从底层原理的角度,探讨Agent Skills是如何工作的。
按照官方定义,Skills是一种基于文件系统的资源,用于为Agent提供特定领域的专业知识,从而将其转变为专家。理解Skills的前提,在于先厘清Agent的基本原理。
ReAct Agent
现代Agent都是基于ReAct模式构建的。ReAct的核心思想是将大语言模型的推理能力(Reasoning)与行动执行(Acting)相结合,使Agent能够反复思考问题、使用工具,并根据观察结果采取行动,从而实现用户目标。
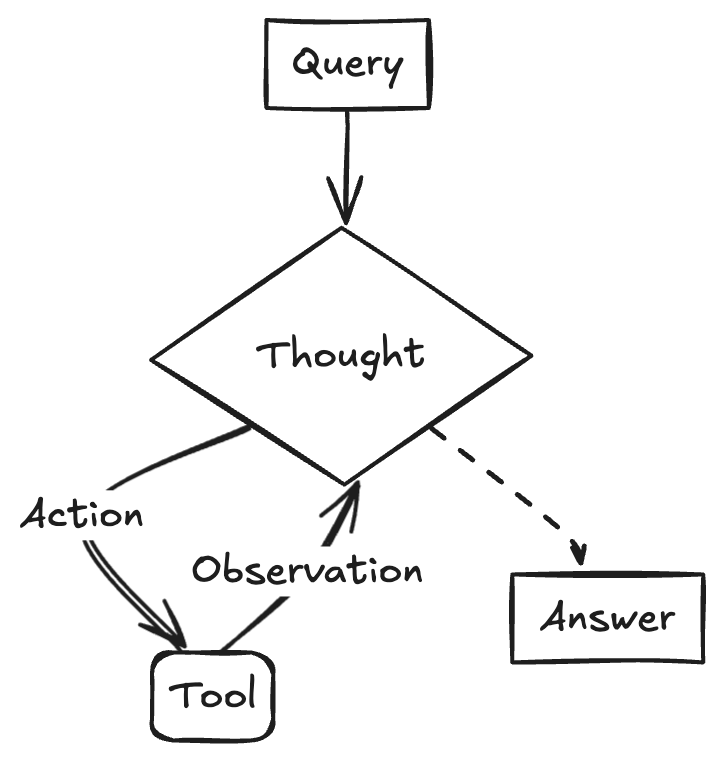
早期采用ReAct模式的Agent,效果并不理想。随着LLM能力的持续演进,特别是函数调用(Function Calling)的引入,ReAct模式的效果得到了显著改善,使得Agent能够更可靠且高效地完成任务。
以天气查询为例,从上下文(Context)的角度来看,ReAct Agent的运行过程大致如下:
1 | System: You are a helpful weather assistant. |
Claude Code
作为一个现代Agent系统,Claude Code也遵循了ReAct模式。我们在揭秘Claude Code:自主式编程中介绍过它的核心架构:
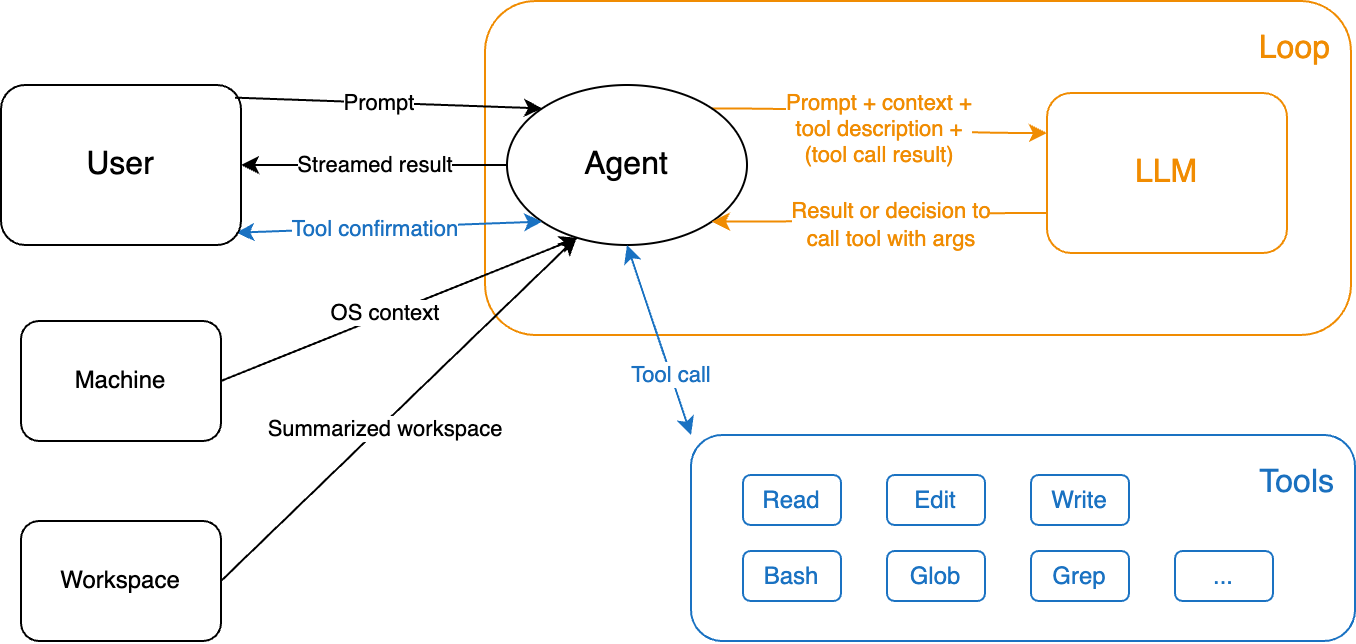
可以看出,Claude Code与常规Agent(如天气查询助手)最大的不同之处在于:它工作在操作系统之上,几乎所有的工具都是围绕文件系统和Shell命令构建而成!
以“查看文件并创建一个Hello World函数”为例,Claude Code运行过程中的Context大致如下:
1 | System: You are Claude Code, Anthropic's official CLI for Claude. |
上下文管理
有了对ReAct Agent和Claude Code的基本认识,我们再来讨论一个关键话题——上下文管理。
了解大语言模型的读者可能知道,LLM的上下文有两个重要特征:
- 上下文窗口大小限制:LLM的上下文窗口大小是有限的(早期GPT 3仅有2048个token),虽然这个大小在持续增长(比如最新Claude Sonnet 4.5已支持百万token),但仍然是有上限的。
- 上下文过载导致性能下降:即使最先进的LLM支持长上下文(如百万token),但如果上下文内容过多,其性能也会显著下降。除了经典的Lost in the Middle,还会出现上下文污染(Context Poisoning)、上下文混淆(Context Confusion)等各种问题。感兴趣的读者可以进一步参考How Long Contexts Fail。
因此,如何有效地管理上下文,成为了Agent设计中的一个重要课题。常见的上下文管理策略包括检索增强(RAG)、上下文总结(Context Summarization)、上下文隔离(Context Quarantine)和上下文卸载(Context Offloading)等。本文的讨论重点关注Context Offloading。
关于Context Offloading,How to Fix Your Context一文给出了以下定义:
上下文卸载(Context Offloading)是指将信息存到LLM的上下文之外,通常借助能管理数据的工具来实现。
而该文引用的Anthropic原文The “think” tool中,则这样指出:
这个“think”工具特别适合用在那些仅凭用户提问、Claude信息不够没法直接回答的情况,还有那些需要处理外部信息(比如工具返回的结果)的场景。比起深度思考那种全面推演,Claude用“think”工具做的推理会更聚焦,主要围绕模型刚发现的新信息展开。
在Claude Code中实现Context Offloading
上述关于Context Offloading的描述稍显抽象。为了便于理解,我们来设想一个问题:如果要让Claude Code支持Context Offloading,应该如何实现?
结合前文的讨论,我们知道Claude Code的能力基本建立在文件系统和Shell命令之上。因此,要实现Context Offloading,从第一性原理出发,我们能够很自然地想到以下方案:
- 将信息存储在文件系统,而不是一开始就全部放到LLM的上下文中;
- 为了让LLM知道这些信息的存在,需要在LLM的上下文中(通常在系统提示词中)记录这些信息的位置;
- 用户提问信息不全时,Agent可以根据系统提示词的引导,按需从文件系统寻找信息;
- 寻找信息的过程,需要借助文件读写和Shell命令等工具;
- 将获取到的外部信息加载到LLM的上下文中,以辅助完成用户的目标。
以“生成博客前端页面”为例,为了不把所有的设计指南都塞到LLM的上下文中,可以将其保存到resources/frontend-design.md文件中:
1 | # Frontend Aesthetics Guidelines |
同时,在Agent的系统提示词中添加对这个文件的引用:
1 | You are Claude Code... |
如此一来,Agent只会在用户请求生成前端页面时,才会去额外读取resources/frontend-design.md文件中的内容,从而避免了不必要的上下文膨胀。具体来说,运行过程中的Context可能会是这样的:
1 | System: You are Claude Code...\n\nYou have access to the following resources:\n- `resources/frontend-design.md`: Guidelines for designing the frontend UI. |
讨论到这里,使用过Skills的读者可能发现了,如果把上述例子中的resources/重命名为skills/,那么frontend-design.md本质上就是一个Skill(参考anthropics/skills/frontend-design/SKILL.md)。
Skills的三层加载技术
至此我们可以看出,Skills的核心思想,其实也遵循了Context Offloading的上下文管理策略。当然,上述例子只是最基础的实现。
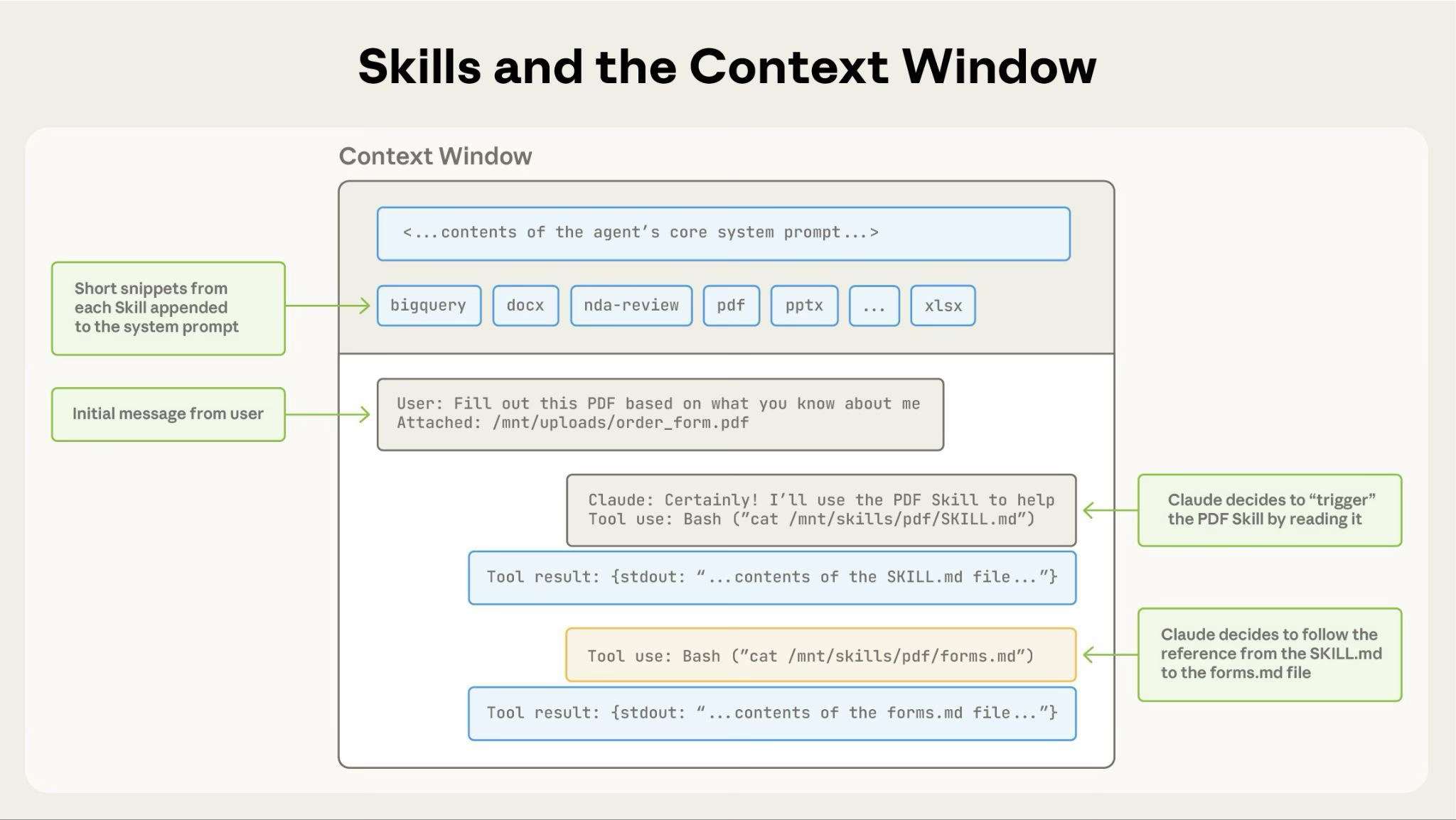
在Anthropic的设计中,又巧妙地引入了Skills的三层加载技术,以求最大化减少LLM上下文的负担:
- 元数据(Metadata):可用Skills的名称、描述及其文件路径。这些信息会被预先放到上下文(系统提示词)中,以确保Agent知道有哪些Skills可以利用。
- 指令(Instructions):每个Skill都有一个对应的
SKILL.md文件,其中包含了Skill的详细描述、使用方法和示例等信息。当Agent需要某个Skill的帮助时,它会通过Read工具读取SKILL.md文件的内容,进而将其动态加载到上下文中。 - 资源(Resources):除了
SKILL.md文件,每个Skill还可以包含其他类型的资源文件,如配置文件、文档等。当Agent需要更具体的信息时,它会进一步读取这些资源文件的内容,从而将其加载到上下文中。
代码执行与虚拟机
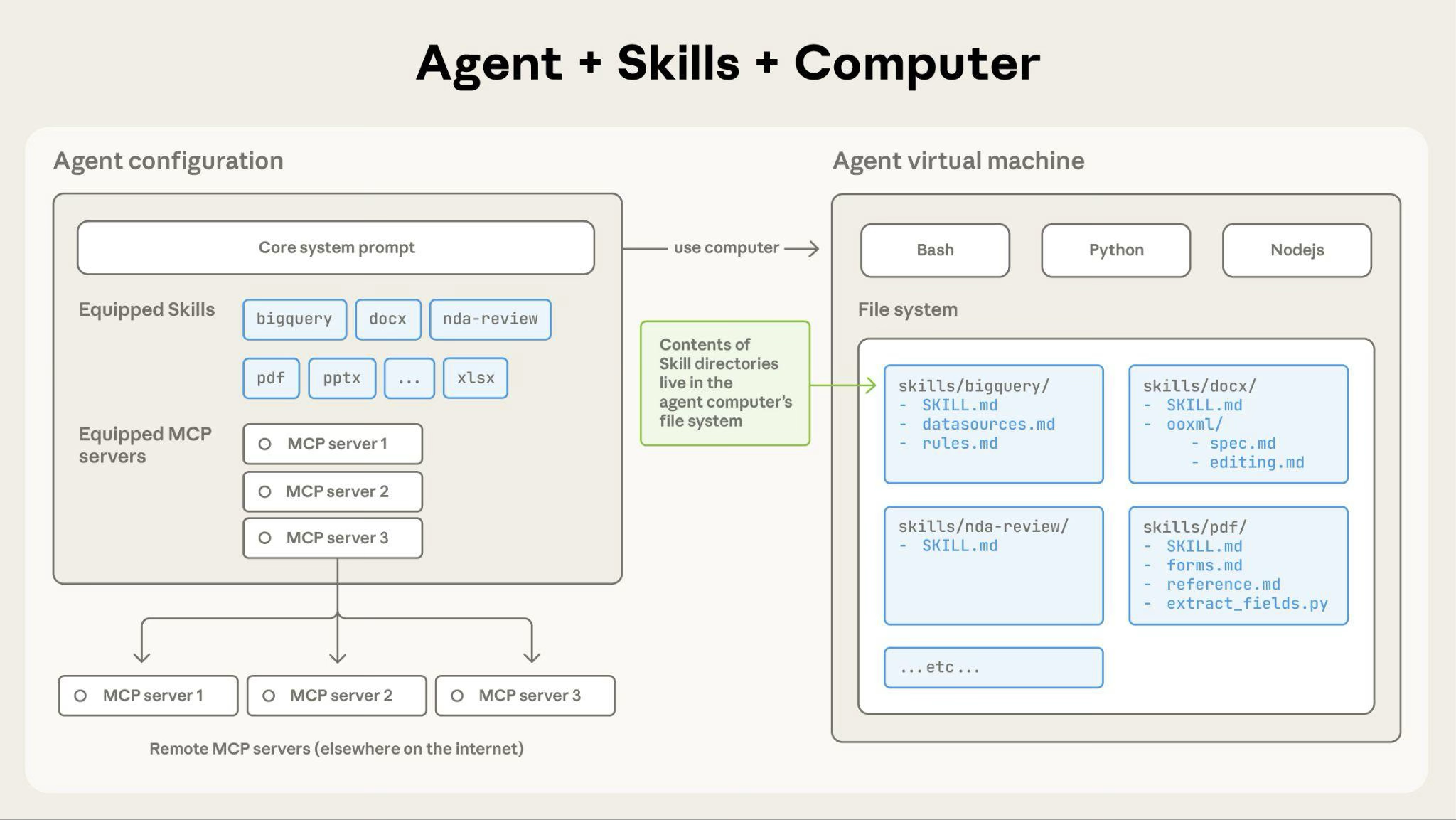
除了前文讨论的内容,需要强调的是,Skills的完整能力还涉及代码执行和虚拟机:
- 代码执行(Code Execution):某些Skills可能包含代码片段,甚至Agent为了处理任务还会动态生成代码,这些代码都需要执行。
- 虚拟机(Virtual Machine):为了确保安全性,通常需要在一个隔离的沙盒环境(虚拟机)中管理文件系统、执行Shell命令和运行代码。
由于篇幅所限,这里不再展开详细讨论,感兴趣的读者可以参考官方文档或者其他相关资料。
结语
通过本文的探讨,相信读者对Agent Skills有了更深入的理解。在Claude Agent产品中,Skills的实现基于Context Offloading这一上下文管理策略;而该策略的落地,则依托于ReAct模式的思想框架,以及文件系统、Shell命令等基础工具的支撑。
此外,代码执行和虚拟机也是非常重要的话题,本文限于篇幅只做了简要提及。实际上,它们不仅是Skills的关键技术,也代表着Agent未来的主流演进方向。在后续的文章中,我们将继续深入探讨这些话题,敬请期待!