Redis replication 揭秘
一、要解决的问题
按照 Redis 官方文档 - Replication 的说法:Redis replication 是一种 master-slave 模式的复制机制,这种机制使得 slave 节点可以成为与 master 节点完全相同的副本。
我们知道,单个 Redis 节点也是可以直接工作的。那为什么一个 Redis 节点(master)还需要一个或多个副本(slave)呢?或者说 replication 到底想要解决什么问题?官方文档如是说:
Replication can be used both for scalability, in order to have multiple slaves for read-only queries (for example, slow O(N) operations can be offloaded to slaves), or simply for improving data safety and high availability.
简而言之,replication 主要用于解决两个问题:
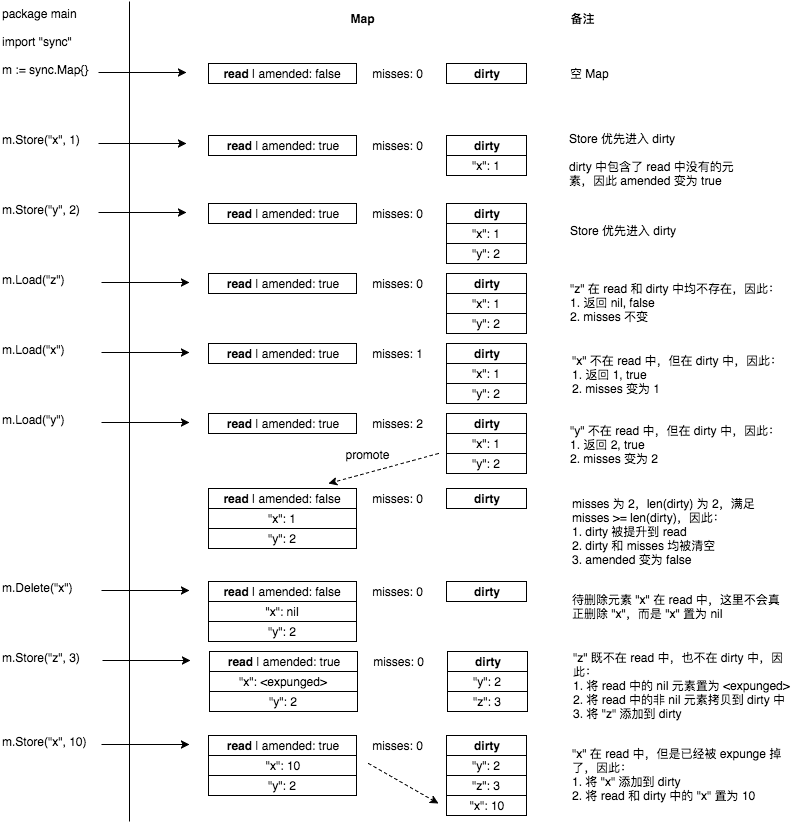
1. 读扩展
一个 master 用于写,多个 slave 用于分摊读的压力。
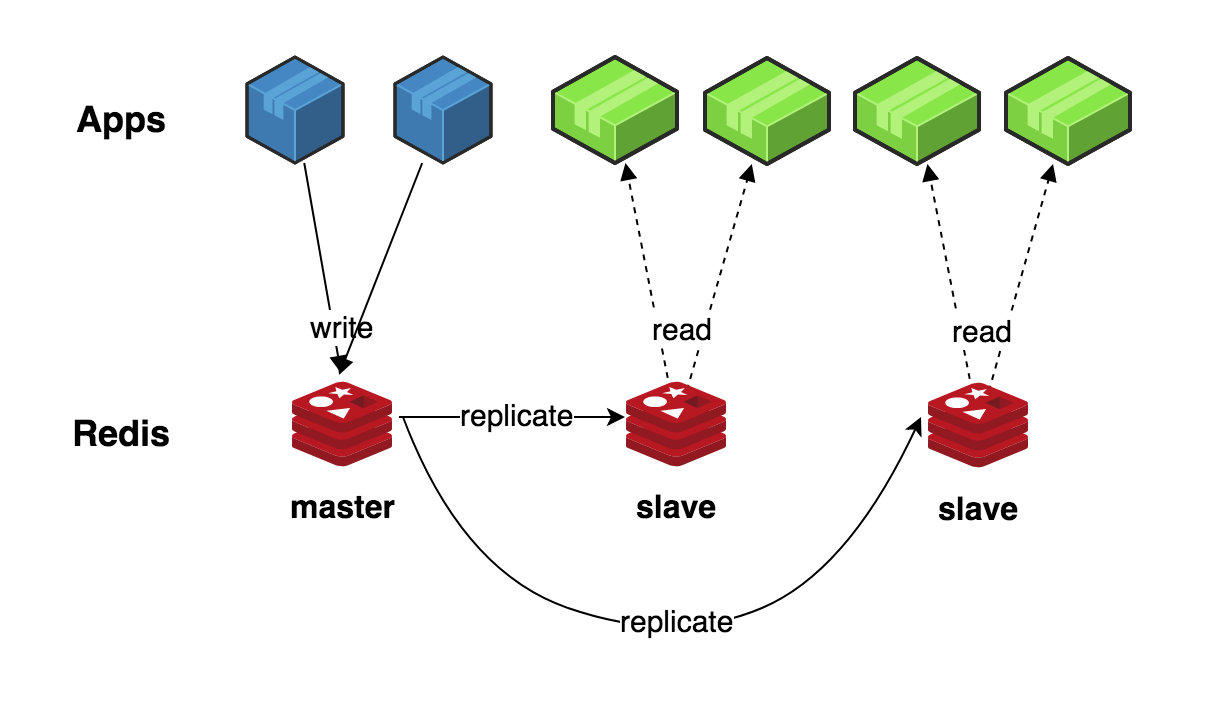
2. 高可用
如果 master 挂掉了,可以提升(promote)一个 slave 为新的 master,进而实现故障转移(failover)。
思考:如果没有 replication,上述两个问题该如何应对?
二、replication 初体验
开两个终端,分别启动一个 Redis 节点:
1 | # Terminal 1 |
在 6379 节点上设置并获取 key1:
1 | $ redis-4.0.8/src/redis-cli -p 6379 |
在 6380 节点上尝试获取 key1:
1 | $ redis-4.0.8/src/redis-cli -p 6380 |
可以看出,两个 Redis 节点各自为政,二者的数据并没有同步。
下面我们让 6380 成为 6379 的 slave 节点:
1 | 127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 |
然后再尝试获取 key1:
1 | 127.0.0.1:6380> GET key1 |
很显然,最初在 6379 节点(后续称为 master)设置的 key1 已经被同步到了 6380 节点(后续称为 slave)。
实验:尝试在 master 设置更多的 key 或删除 key,然后在 slave 上获取并观察结果。
三、情景分析
1. slave 初次连接 master
上述过程中,在 slave 上执行 SLAVEOF 命令以后,可以看到 slave 的日志如下:
1 | 31667:S 03 Jul 21:32:17.809 * Before turning into a slave, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer. |
对应 master 的日志如下:
1 | 31655:M 03 Jul 21:32:17.826 * Slave 127.0.0.1:6380 asks for synchronization |
分析上述输出日志,我们可以初步总结出 slave 和 master 的交互时序:
- slave 主动连接 master。
- 连接成功后,slave 会向 master 发起 partial resynchronization 的请求。
- master 收到请求后,判断 replication ID 不匹配,拒绝执行 partial resynchronization,转而通知 slave 执行 full resync。
- 随后 master 开始执行 BGSAVE 命令,将当前 DB 数据保存到 disk 磁盘,最后向 slave 发送 DB 数据。
- slave 从 master 接收到 DB 数据后,将其加载到内存,同时删除旧数据。
2. slave 断开后重连 master
思考:在同一台机器上,如何模拟 master 和 slave 的网络断开与恢复?
master 日志:
1 | 33518:M 03 Jul 22:46:48.432 # Disconnecting timedout slave: 127.0.0.1:6380 |
slave 日志:
1 | 33519:S 03 Jul 22:46:48.432 # Connection with master lost. |
可以看出:
- 网络断开一段时间后,master 会断开与 slave 的连接。
- 网络恢复后,仍然是 slave 主动连接 master。
- 连接成功后,slave 会向 master 发起 partial resynchronization 的请求。
- 这一次,master 接受了该 partial resynchronization 请求,然后将 backlog 中由 (offset, size) 标记的数据流发送给 slave。
- slave 从 master 接收到数据流后,更新自己内存中的数据。
实验:redis.conf 中有两个参数 repl-timeout(默认值为 60 秒)和 repl-backlog-ttl(默认值为 3600 秒),尝试都设置为 10 秒,然后断开网络一直等到 25 秒后再恢复,再观察 master 和 slave 的日志会有什么不同?
3. master 与 slave 连接正常,写 master
通过 telnet 连接到 master:
1 | $ telnet 127.0.0.1 6379 |
键入 PSYNC 命令,尝试与 master 进行同步:
1 | $ telnet 127.0.0.1 6379 |
此时查看 master 的日志:
1 | 40535:M 07 Jul 17:04:51.009 * Slave 127.0.0.1:<unknown-slave-port> asks for synchronization |
随后在 master 上设置 key2:
1 | 127.0.0.1:6379> SET key2 value2 |
然后观察 telnet 的输出:
1 | $ telnet 127.0.0.1 6379 |
可以看出:
- telnet 通过 PSYNC 命令,成为了 master 的一个新的 slave。
- master 上的写命令(这里是
SET key2 value2),会被传播(propagate)到 salve 上,进而保证了 slave 与 master 的数据一致性。
四、replication 原理
上面的三种情景,其实已经涵盖了 Redis replication 的两大核心操作:
- 重同步(resync)
- 完整重同步(full resynchronization)
- 部分重同步(partial resynchronization)
- 命令传播(command propagate)
下面我们对这两种操作,做进一步阐述。
1. 重同步
「重同步」用于将 slave 的数据库状态更新至 master 当前所处的数据库状态。
SYNC 与 PSYNC
旧版本 Redis 中,「重同步」通过 SYNC 命令来实现。从 2.8 版本开始,Redis 改用 PSYNC 命令来代替 SYNC 命令。
SYNC 命令和 PSYNC 命令的区别:
| 命令 | 初次复制 | 断线后复制 |
|---|---|---|
| SYNC | 完整重同步 | 完整重同步 |
| PSYNC | 完整重同步:PSYNC ? -1 |
部分重同步:PSYNC <replication-id> <offset> |
完整重同步
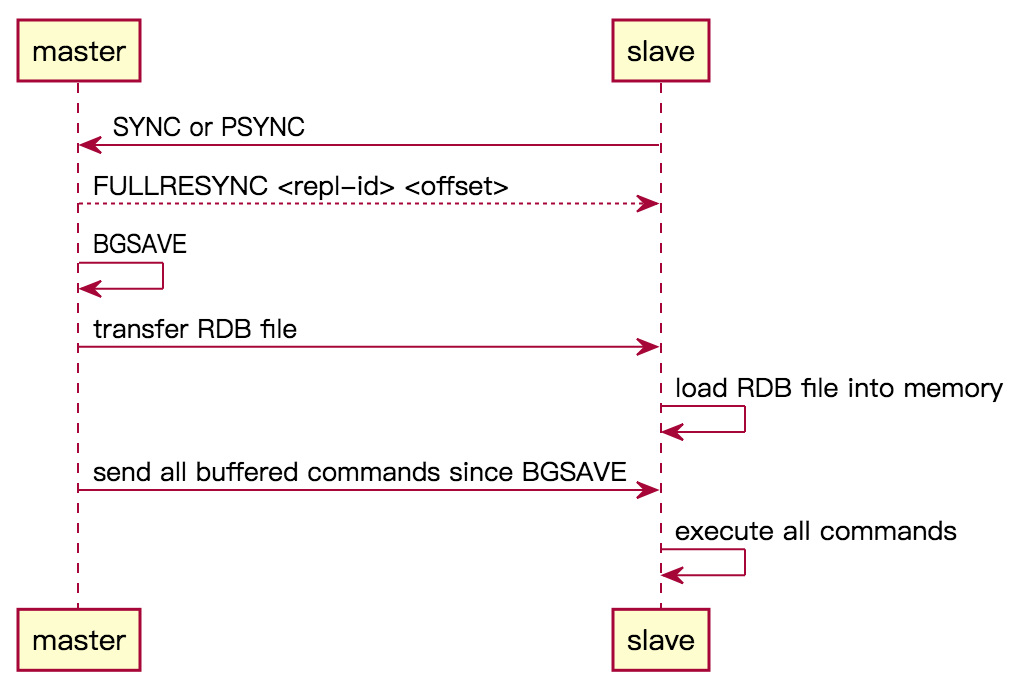
说明:
- slave 通过 SYNC 或 PSYNC 命令,向 master 发起同步请求。
- master 返回 FULLRESYNC 告知 slave 将执行「完整重同步」,先决条件为:
- 请求命令是「完整重同步」SYNC。
- 请求命令是「完整重同步」
PSYNC ? -1。 - 请求命令是「部分重同步」
PSYNC <replication-id> <offset>,但是<replication-id>不是 master 的 replication-id,或者 slave 给的<offset>不在 master 的「复制积压缓冲区」backlog 里面。
- master 执行 BGSAVE 命令,将当前数据库状态保存为 RDB 文件。
- 生成 RDB 文件完毕后,master 将该文件发送给 slave。
- slave 收到 RDB 文件后,将其加载至内存。
- master 将 backlog 中缓冲的命令发送给 slave(一开始在 BGSAVE 时记录了当时的 offset)。
- slave 收到后,逐个执行这些命令。
部分重同步
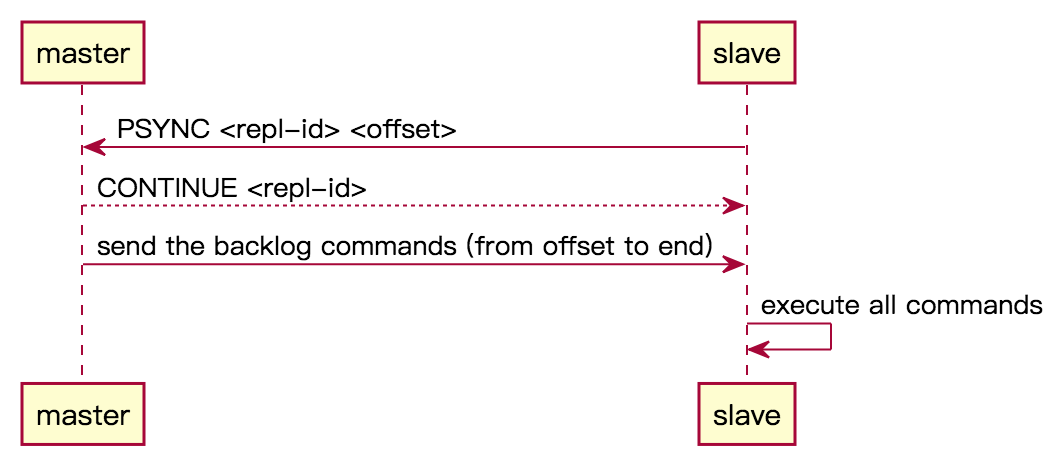
说明:
- slave 通过
PSYNC <replication-id> <offset>命令,向 master 发起「部分重同步」请求。 - master 返回 CONTINUE 告知 slave 同意执行「部分重同步」,先决条件为:
<replication-id>是 master 的 replication-id,并且 slave 给的<offset>在 master 的「复制积压缓冲区」backlog 里面
- master 将 backlog 中缓冲的命令发送给 slave(根据 slave 给的 offset)。
- slave 收到后,逐个执行这些命令。
由上可以看出,「复制积压缓冲区」backlog 是「部分重同步」得以实现的关键所在。
复制积压缓冲区
「复制积压缓冲区」是 master 维护的一个固定长度(fixed-sized)的先进先出(FIFO)的内存队列。值得注意的是:
- 队列的大小由配置
repl-backlog-size决定,默认为 1MB。当队列长度超过repl-backlog-size时,最先入队的元素会被弹出,用于腾出空间给新入队的元素。 - 队列的生存时间由配置
repl-backlog-ttl决定,默认为 3600 秒。如果 master 不再有与之相连接的 slave,并且该状态持续时间超过了repl-backlog-ttl,master 就会释放该队列,等到有需要(下次又有 slave 连接进来)的时候再创建。
master 会将最近接收到的写命令(按 Redis 协议的格式)保存到「复制积压缓冲区」,其中每个字节都会对应记录一个偏移量 offset。
| . | . | . | . | . | . | . | . | . | . | . | . | . | . |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 偏移量 | … | 10087 | 10088 | 10089 | 10090 | 10091 | 10092 | 10093 | 10094 | 10095 | 10096 | 10097 | … |
| 字节值 | … | ‘*’ | 3 | ‘\r’ | ‘\n’ | ‘$’ | 3 | ‘\r’ | ‘\n’ | ‘S’ | ‘E’ | ‘T’ | … |
与此同时,slave 会维护一个 offset 值,每次从 master 传播过来的命令,一旦成功执行就会更新该 offset。尝试「部分重同步」的时候,slave 都会带上自己的 offset,master 再判断 offset 偏移量之后的数据是否存在于自己的「复制积压缓冲区」中,以此来决定执行「部分重同步」还是「完整重同步」。
2. 命令传播
「命令传播」用于在 master 的数据库状态被修改时,将导致变更的命令传播给 slave,从而让 slave 的数据库状态与 master 保持一致。
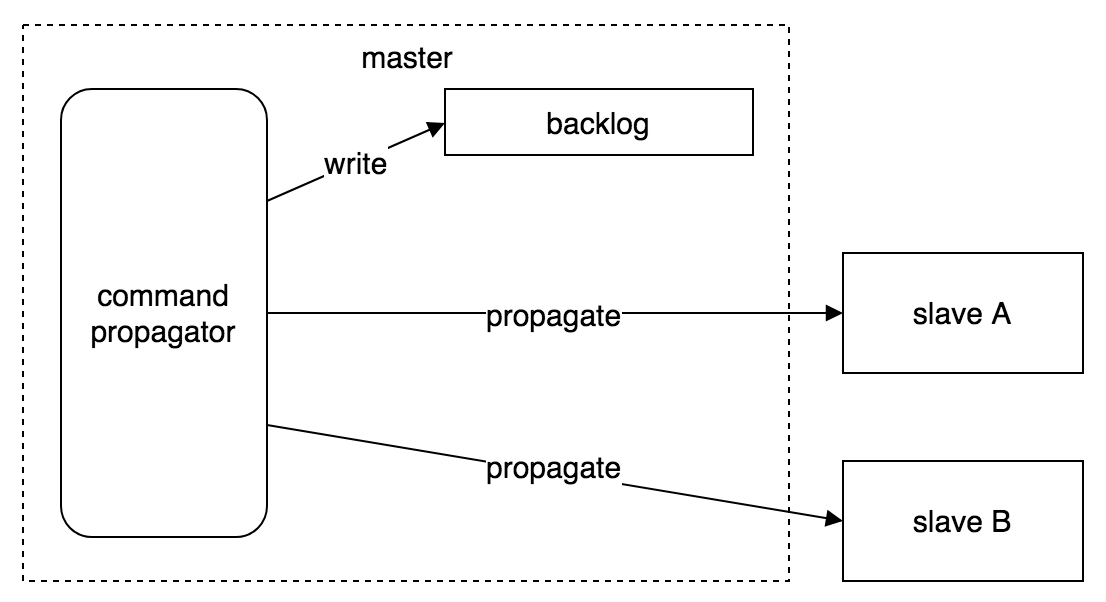
说明:master 进行命令传播时,除了将写命令直接发送给所有 slave,还会将这些命令写入「复制积压缓冲区」,用于后续可能发生的「部分重同步」操作。