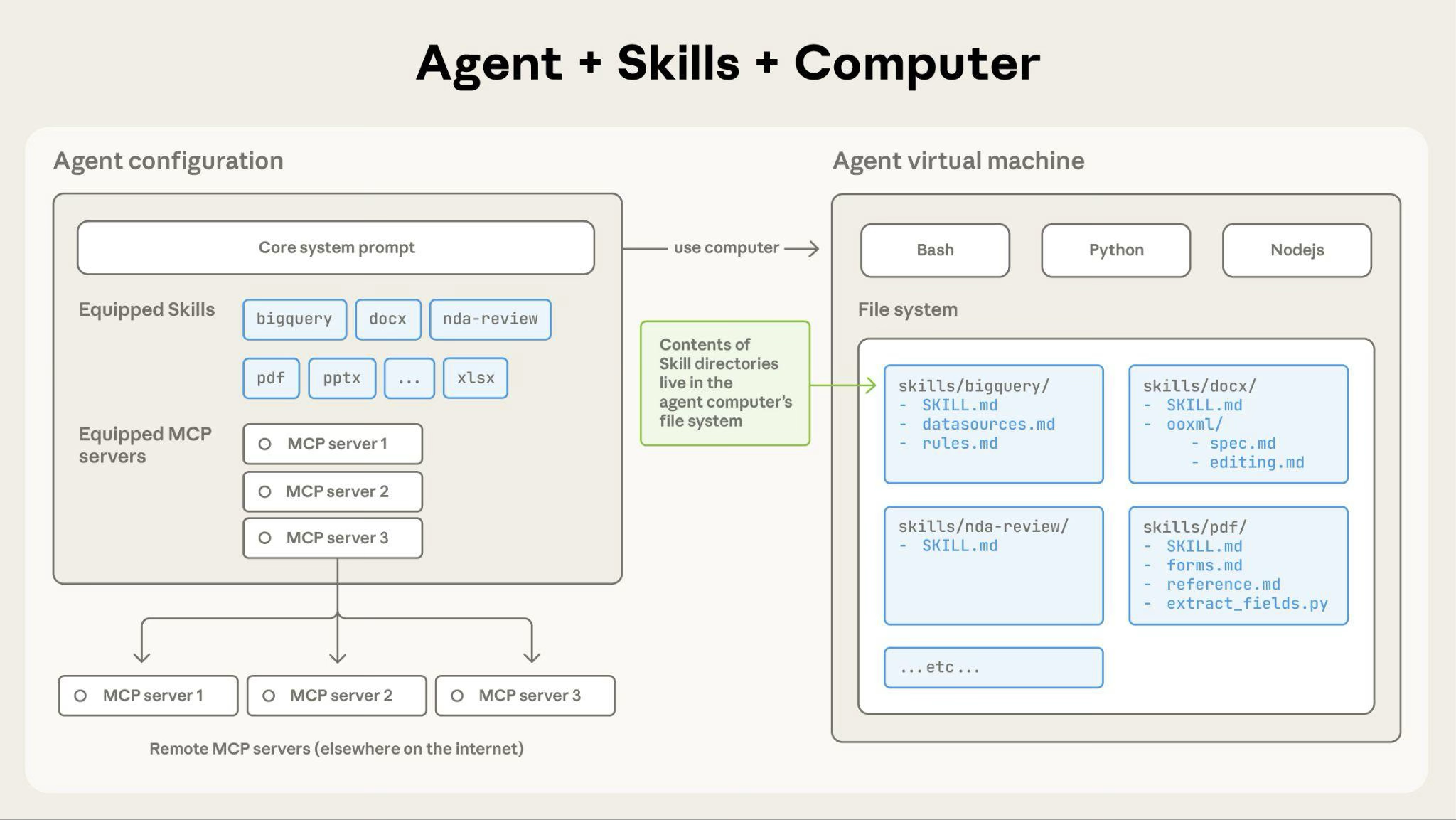
--- name:dev-workflow description:Completedevelopmentworkflowforhandlingissues. --- You help developers with three workflow tasks:
1. Issue to Code:Generatecodefromissuedescription. 2. Code to Tests:Generatetestsforthegeneratedcode. 3. Code to Review:Performcodereviewonthegeneratedcode.
1. Issue to Code:Usethe`code-developer`agenttogeneratecodefromtheissuedescription. 2. Code to Tests:Usethe`code-tester`agenttogeneratetestsforthegeneratedcode. 3. Code to Review:Usethe`code-reviewer`agenttoperformcodereviewonthegeneratedcode.
[System] You are Claude Code. [User] Complete issue.md [Tool Call] Read(.claude/skills/effective-dev-workflow/SKILL.md) [Tool Output] <the skill instructions> [Tool Call] Read(issue.md) [Tool Output] <issue description> [Tool Call] Task(code-developer, "Generate code and save it as code.py") [Tool Output] <final output fromcode-developer> [Tool Call] Task(code-tester, "Generate tests for the code in code.py and save them as tests.py") [Tool Output] <final output fromcode-tester> [Tool Call] Task(code-reviewer, "Perform code review on the code in code.py and save the report as review.md") [Tool Output] <final output fromcode-reviewer> [Assistant] <final conclusion>
开发Subagent的Context:
1 2 3 4 5 6
[System] You are Claude Code.\nYou are acode developer... [User] Generate code and save it as code.py [Assistant] <generated code> [Tool Call] Write(code.py) [Tool Output] <success> [Assistant] <final output>
测试Subagent的Context:
1 2 3 4 5 6 7 8 9 10
[System] You are Claude Code.\nYou are acode tester... [User] Generate tests for the codeincode.py and save them as tests.py [Tool Call]Read(code.py) [Tool Output] <codecontent> [Assistant] <generated tests> [Tool Call]Write(tests.py) [Tool Output] <success> [Tool Call]Bash(python tests.py) [Tool Output] <test results> [Assistant] <final output>
审查Subagent的Context:
1 2 3 4 5 6 7 8
[System] You are Claude Code.\nYou are acode reviewer... [User] Perform code review on the codeincode.py and save the report as review.md [Tool Call]Read(code.py) [Tool Output] <codecontent> [Assistant] <generated review report> [Tool Call]Write(review.md) [Tool Output] <success> [Assistant] <final output>
Thereisa {project_root}/NOTES.mdfile that records the progress of the task: -Pleasereviewthisfilebeforestartingthetask. -Aftercompletingthetask,recordthekeyprogressinthisfile.
Thereisa {project_root}/NOTES.mdfile that records the progress of the task: -Pleasereviewthisfilebeforestartingthetask. -Aftercompletingthetask,recordthekeyprogressinthisfile.
Thereisa {project_root}/NOTES.mdfile that records the progress of the task: -Pleasereviewthisfilebeforestartingthetask. -Aftercompletingthetask,recordthekeyprogressinthisfile.
# Task Progress ## Completed Tasks ### 2026-03-08: Generated code and created code.py
测试Skill的Context:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
[System] You are Claude Code. [User] Generate tests for code.py [Tool Call]Read(.claude/skills/code-tester/SKILL.md) [Tool Output] <the skill instructions> [Tool Call]Read(code.py) [Tool Output] <codecontent> [Tool Call]Read(NOTES.md) [Tool Output] <notes content> [Assistant] <generated tests> [Tool Call]Write(tests.py) [Tool Output] <success> [Tool Call]Bash(python tests.py) [Tool Output] <test results> [Tool Call]Edit(NOTES.md, "\n### 2026-03-08: Generated tests and created tests.py") [Tool Output] <success> [Assistant] <final output>
此时,NOTES.md的内容如下:
1 2 3 4
# Task Progress ## Completed Tasks ### 2026-03-08: Generated code and created code.py ### 2026-03-08: Generated tests and created tests.py
审查Skill的Context:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
[System] You are Claude Code. [User] Perform code review on code.py [Tool Call]Read(.claude/skills/code-reviewer/SKILL.md) [Tool Output] <the skill instructions> [Tool Call]Read(code.py) [Tool Output] <codecontent> [Tool Call]Read(NOTES.md) [Tool Output] <notes content> [Assistant] <generated review report> [Tool Call]Write(review.md) [Tool Output] <success> [Tool Call]Edit(NOTES.md, "\n### 2026-03-08: Performed code review and created review.md") [Tool Output] <success> [Assistant] <final output>
此时,NOTES.md的内容如下:
1 2 3 4 5
# Task Progress ## Completed Tasks ### 2026-03-08: Generated code and created code.py ### 2026-03-08: Generated tests and created tests.py ### 2026-03-08: Performed code review and created review.md
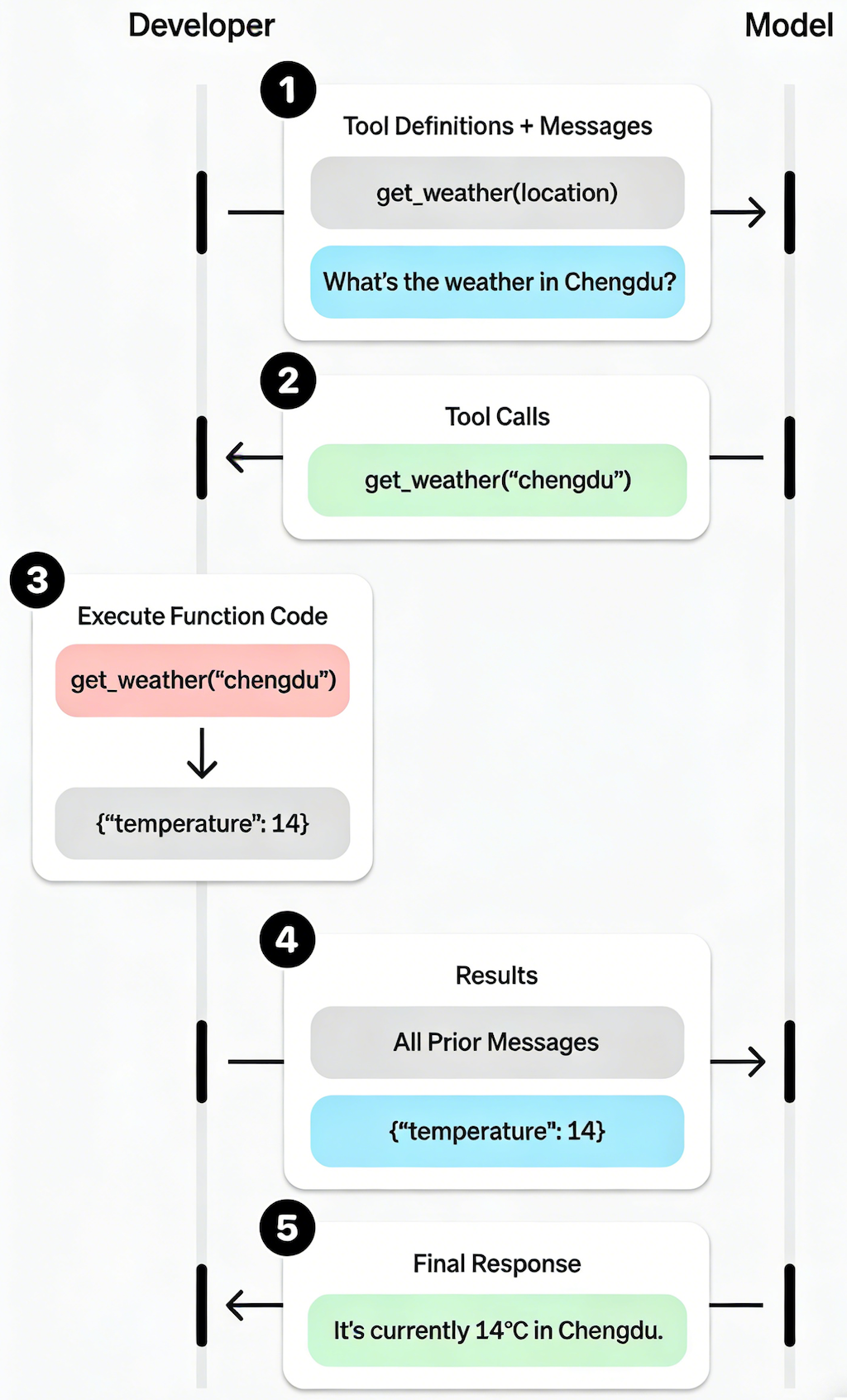
# 1. Define a list of callable tools for the model # (Note that `parameters` are defined in JSON Schema) tools = [ { "type": "function", "name": "get_weather", "description": "Retrieves current weather for the given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "City e.g. Beijng, Chegndu" } }, "required": ["location"], "additionalProperties": False }, "strict": True }, ]
defget_weather(location: str) -> str: # Here you would normally make an API call to a weather service return'{"temperature": 14}'
# Create a running input list we will add to over time input_list = [ {"role": "user", "content": "What is the weather like in Chengdu?"}, ]
# 2. Prompt the model with tools defined response = client.responses.create( model="gpt-5", tools=tools, input=input_list, )
# Save function call outputs for subsequent requests input_list += response.output
for item in response.output: if item.type == "function_call": if item.name == "get_weather": # 3. Execute the function logic for `get_weather` location = json.loads(item.arguments)["location"] output = get_weather(location) # 4. Provide function call results to the model input_list.append({ "type": "function_call_output", "call_id": item.call_id, "output": output, })
response = client.responses.create( model="gpt-5", instructions="You are a helpful assistant.", tools=tools, input=input_list, )
# 5. The model should be able to give a response! print(response.output_text)
# Output: # The current temperature in Chengdu is about 14°C.
from langchain.chat_models import init_chat_model from langchain.tools import tool
model = init_chat_model("gpt-5")
@tool defget_weather(location: str) -> str: """Retrieves current weather for the given location.""" returnf"It's sunny in {location}."
# 1. Bind (potentially multiple) tools to the model model_with_tools = model.bind_tools([get_weather])
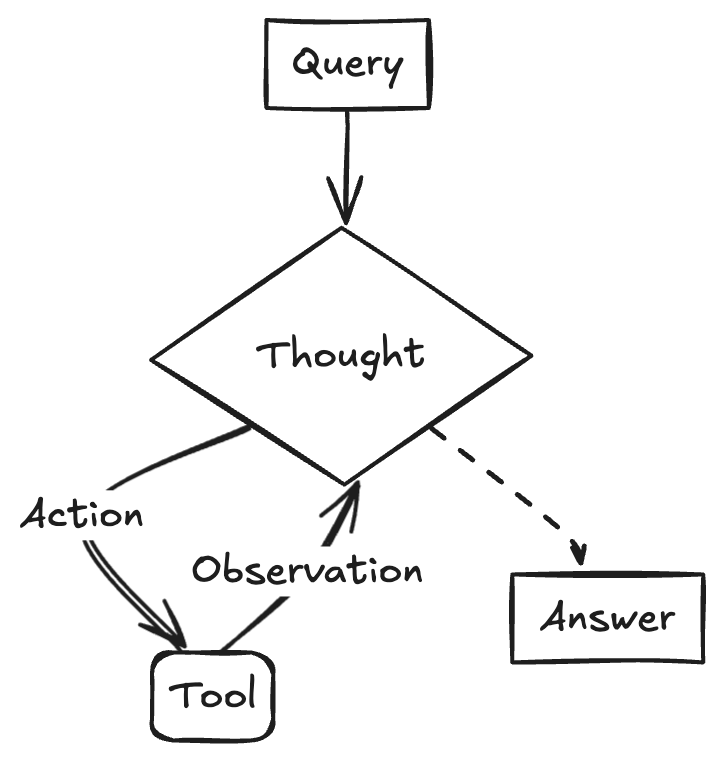
# 2. Model generates tool calls messages = [{"role": "user", "content": "What's the weather like in Chengdu?"}] ai_msg = model_with_tools.invoke(messages) messages.append(ai_msg)
for tool_call in ai_msg.tool_calls: # 3. Execute the tool with the generated arguments tool_result = get_weather.invoke(tool_call) # 4. Pass results back to model messages.append(tool_result)
# 5. Model generates the final response final_response = model_with_tools.invoke(messages) print(final_response.text)
from langchain.agents import create_agent from langchain.chat_models import init_chat_model from langchain.tools import tool
model = init_chat_model("gpt-5")
@tool defget_weather(location: str) -> str: """Retrieves current weather for the given location.""" returnf"It's sunny in {location}."
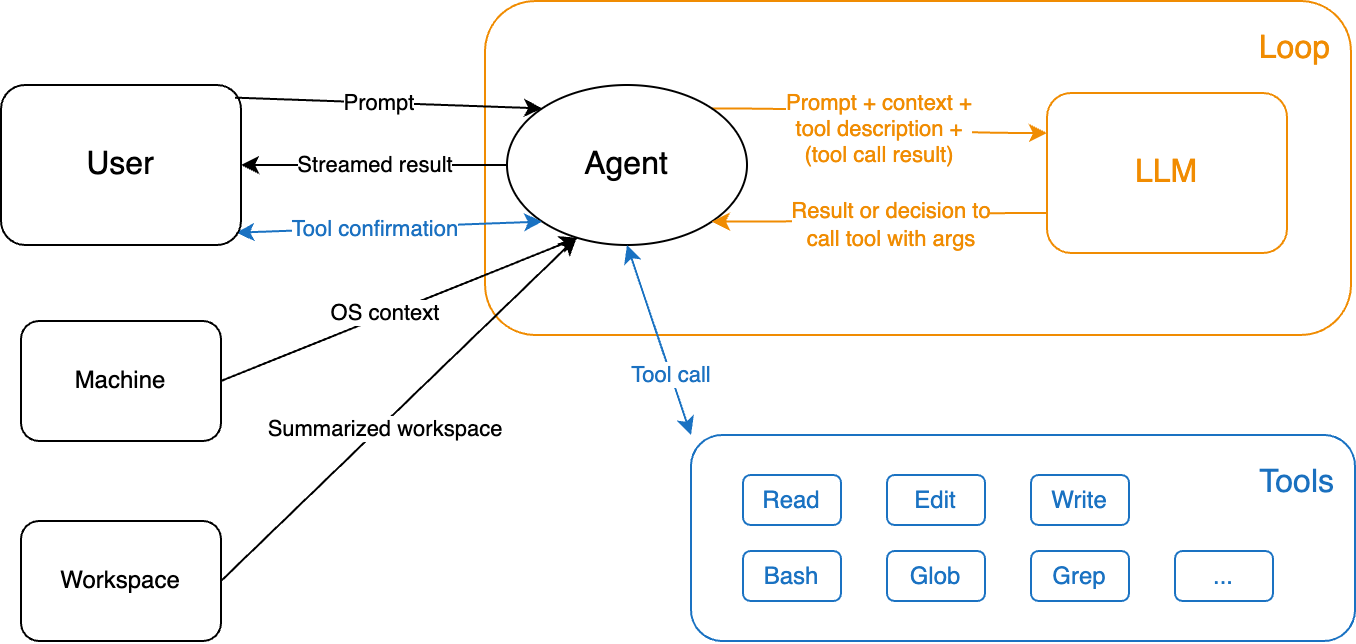
agent = create_agent(model, tools=[get_weather]) result = agent.invoke( {"messages": [{"role": "user", "content": "What's the weather like in Chengdu?"}]} ) print(result["messages"][-1].content)
System: You are a helpful weather assistant. User: What is the weather like in Chengdu? Assistant: ToolCall(name="get_weather", args={"location": "Chengdu"}) User: ToolOutput(result={"weather": "Sunny", "temperature": "22°C"}) Assistant: The weather in Chengdu is Sunny with a temperature of 22°C.
System: You are Claude Code, Anthropic's official CLI for Claude. User: What files are there? Assistant: ToolCall(name="Bash", args={"command": "ls"}) User: ToolOutput(result="[README.md]") Assistant: There is only one file named README.md. User: Create a hello world function in Python. Assistant: ToolCall(name="Write", args={"file_path": "hello_world.py", "content": "def hello_world():\n print('Hello, World!')\n\nif __name__ == '__main__':\n hello_world()"}) User: ToolOutput(result="Created `hello_world.py` with a simple hello world function.") Assistant: I've created a simple Python file with a "Hello, World!" function.
上下文过载导致性能下降:即使最先进的LLM支持长上下文(如百万token),但如果上下文内容过多,其性能也会显著下降。除了经典的Lost in the Middle,还会出现上下文污染(Context Poisoning)、上下文混淆(Context Confusion)等各种问题。感兴趣的读者可以进一步参考How Long Contexts Fail。
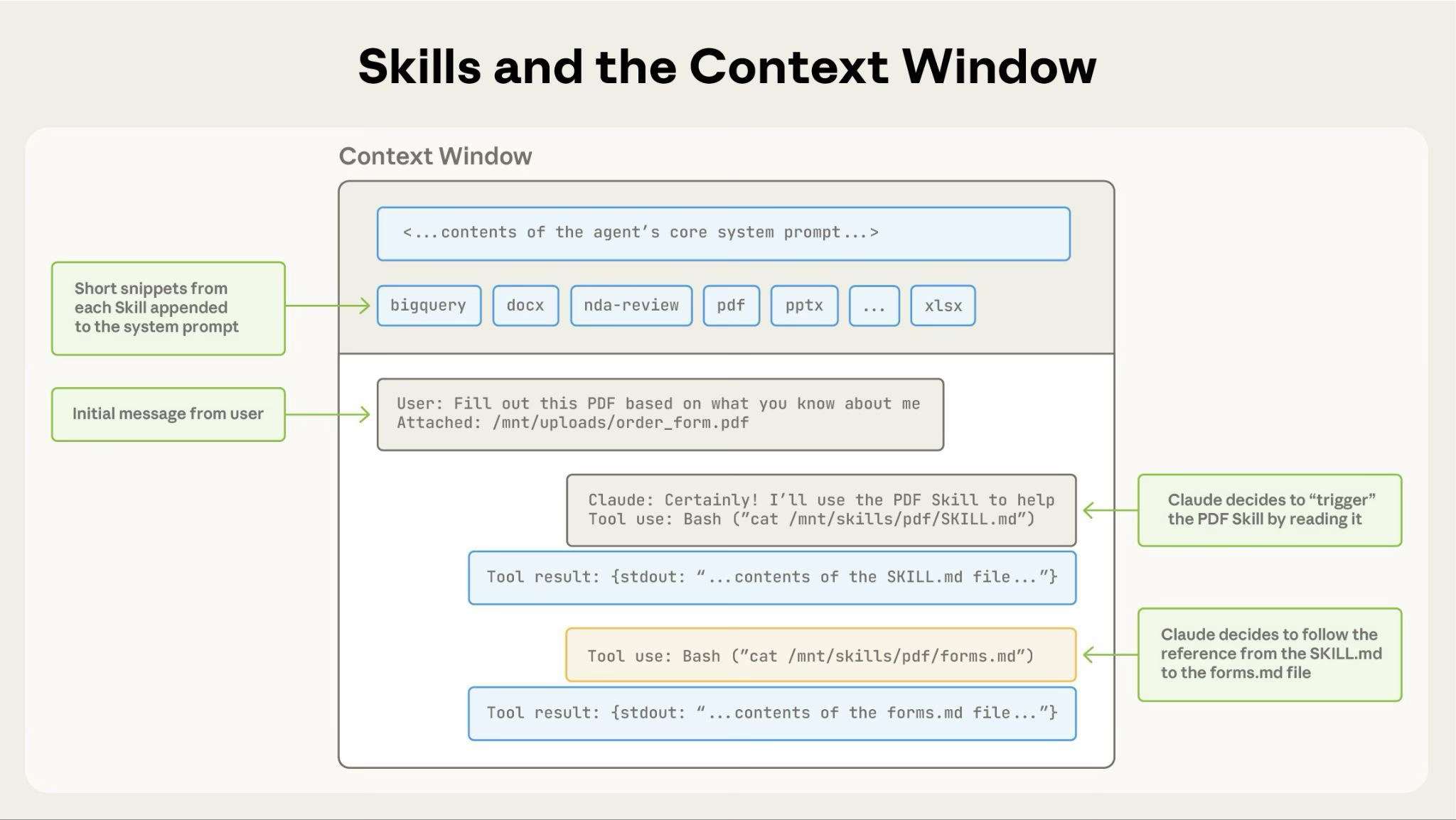
System: You are Claude Code...\n\nYou have access to the following resources:\n- `resources/frontend-design.md`: Guidelines for designing the frontend UI. User: Generate a blog frontend UI. Assistant: ToolCall(name="Read", args={"file_path": "resources/fontend-design.md"}) User: ToolOutput(result="Choose fonts that are beautiful, unique, and interesting...") Assistant: ToolCall(name="Write", args={"file_path": "app/index.html", "content": "<html><head><style>...</style></head><body>...</body></html>"}) User: ToolOutput(result="Created file `app/index.html`.") Assistant: ToolCall(name="Write", args={"file_path": "app/styles.css", "content": "..."}) User: ToolOutput(result="Created file `app/styles.css`.") Assistant: I've generated a simple blog frontend UI based on the guidelines.